| 【机器学习】LSTM算法原理及加速算法 | 您所在的位置:网站首页 › lstm 优化器 › 【机器学习】LSTM算法原理及加速算法 |
【机器学习】LSTM算法原理及加速算法
|
LSTM算法介绍
这里有一本书,是由Jason Brownlee所著《Long Short Term Memory Networks with Python》,里面详细 介绍了lstm相对于mlp的优势及前向后向算法。 下面给出我的csdn链接(感谢支持)和百度云链接,大家按需自取就好。 https://download.csdn.net/download/kouqikamalu/19359306 链接:https://pan.baidu.com/s/1kT0KAGGNew3BkFByi6os2A 提取码:kets lstm加速我们按照以下几个方面: 1. lstm为什么慢 2. 硬件加速 3. 算法加速 lstm的先天性一般大家见惯了lstm示意图,很了解隐藏层神经元是一个的情况,那如果是多个呢,输入神经元 数目又是否能是多个呢?
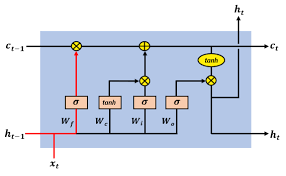
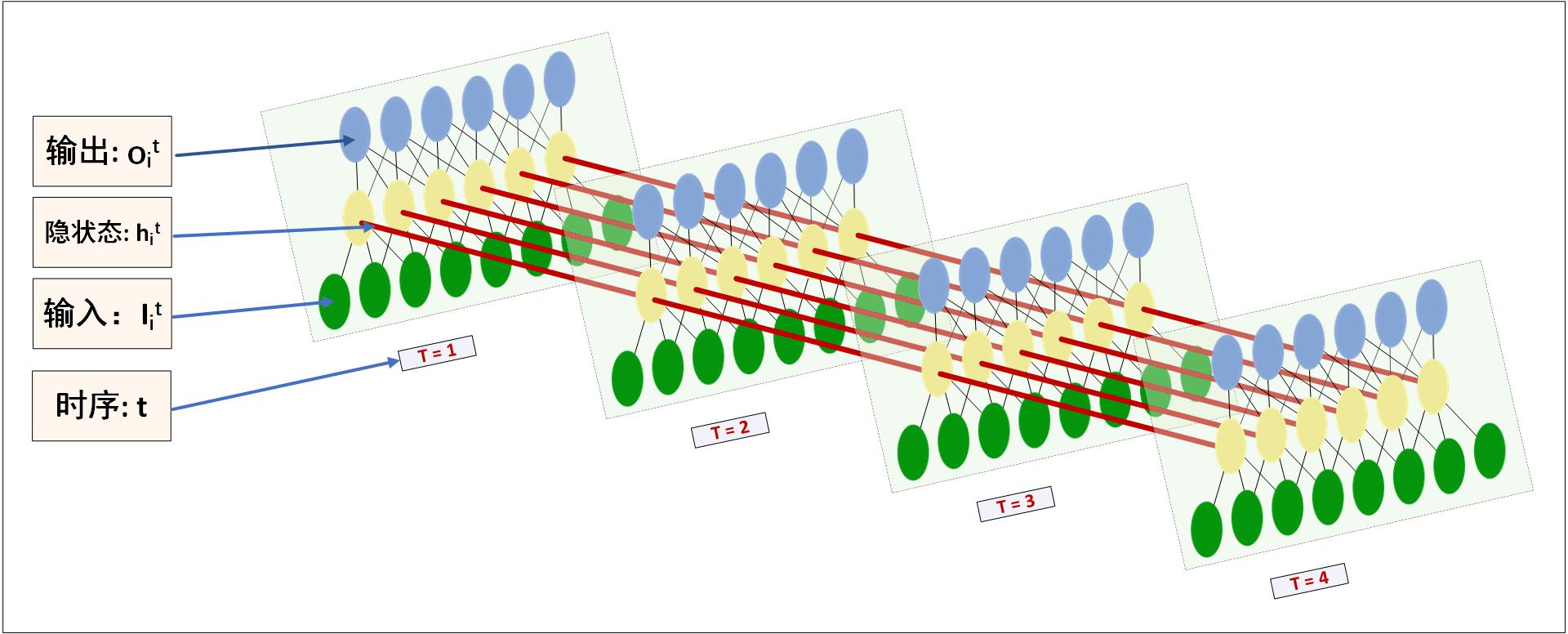
(图片来源 https://medium.datadriveninvestor.com/how-do-lstm-networks-solve-the-problem-of-vanishing -gradients-a6784971a577) 我们现在来说明一下,首先lstm的输入神经元个数可以任意的,可以同时输入多个;第二,隐藏层 神经元个数可以是多个,像下图所示:
(图片来自 《LSTM神经网络输入输出究竟是怎样的?》 - Scofield的回答 - 知乎 https://www.zhihu.com /question/41949741/answer/318771336) 我们设置输入个数为5,滑动步长任意,时间序列为[a1,a2,a3,a4,...]。隐藏层个数为10.
(图片转自https://www.rs-online.com/designspark/predicting-weather-using-lstm) 那么ht-1为10维,xt为5维,所以我们可以得到 这里wf,bf,大家可以从第一张图中看到。[ht-1,xt]是一个1*15维的向量,要想得到神经元数目为10 的隐藏层,Wf的大小应为15*10,bf为1*10维。 其中*为对应元素相乘,而非矩阵运算。 接下来是输入门: 这里的参数我们同样可以计算是2*(15*10+10)。 最后是输出层, 参数为15*10+10。所以一层lstm相当于4层mlp,因为要做四次矩阵运算,参数量也变成了4倍。 lstm的增高鞋硬件加速的工具主要就是GPU,现在cudnn已支持使用GPU运行lstm网络,相对于cpu,运行速度 快了将近6倍。这主要是通过将四次矩阵运算在GPU中并行处理,即由于同一个输入[ht-1,xt],所以 可以把[Wf,Wi,Wc,Wo]也合并起来,这样运算后,输出也变成了4倍。 另外,cudnn支持的GPU还有另一个优势,那就是多个Stream的使用。一般来说,GPU和CPU不能 直接读取对方的内存,所以需要先将数据从CPU内存转移到GPU内存,在GPU中进行运算保存,然后 将结果从GPU内存拷贝到CPU内存。并且在GPU计算的时候,是不能将已算好的数据从GPU转到CPU。 多个streem的含义就是实现在GPU计算的同时,也能实现数据的转移。在1个streem在完成上边三个步 骤的时候,并不影响其他streem,可以计算,可以转存到CPU,也可以转存到GPU。
(图片来源 https://zhuanlan.zhihu.com/p/51402722) lstm的高乐高虽然我们尽量利用GPU的并行化,通过以下方式。 (图片来源 https://blog.csdn.net/SYSU_BOND/article/details/101156567) 另一部分就是算法提升,主要是有两个算法,一个是GRNN,一个是CRU。 GRNNhttps://my.oschina.net/u/4611803/blog/4669665 论文见: 链接:https://pan.baidu.com/s/1srsIGlREG5qpGa3i6EAExw 提取码:92xq CRU(待)
|


【本文地址】